Background
When I was at a boarding house, I had this pile of receipts piling up inside my wallet. I was thinkin gof dumping them into the dustbin. However, I was thinking what if I store them somehwere else instead to track my monthly outcome. Now that an idea came up, I could just throw them to OpenClaw and connect it to my telegram, then it's all done. Even so, the token consumed by the LLM would be a huge issue and there was no way to continue with OpenClaw, so I thought of another alternative by using OCR. now, the LLM's role is just to parse what is processed by the OCR. so I proceeded with this idea


Ideate an app
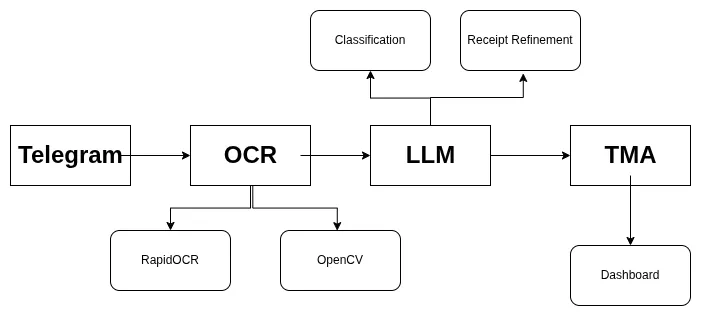
The app's flow initiates a user sending a photo to telegram, as it's sent, it will be processed by the ml-service, or the RapidOCR and LLM. I also needed an OpenCV as an additional guards if the receipts were not in good conditions. After processing, Telegram will return an output of merchant, items, and the total price. These data are also sent to the backend to be stored into a database. Finally, the data will be visualized through frontend in the view of dashboard. Here, users will also able to edit their data if the output by Telegram makes mistake.
What to solve
i'm trying to solve my own problem where I can store any store's receipts and track my monthly outcome. I want it to be useful, at least for myself. yes, there are other similar apps that are maybe better than mine, but this one is specifically designed for what I need. I need an OCR to scan the receipt, a cloud LLM for free and is designed to only parse the OCR, so the token usage is low, and a dashboard directly connected to my Telegram, so that I can do everything in one environment without the need of opening any external browsers.
Challenges
It is without doubt that there are challenges I faced during the development of this app. First, the receipt itself. Receipts come with different layouts and it is challenging for the ocr to match with the desired output. one receipt comes in, it may output what is desired, another different receipt layout comes in, and it may return missing information. Besides, receipts that are not in good conditions, such as blurry, torn, creased, or crumpled also contribute to bad OCR output. Finally, LLM. just because there's an LLM to parse, it doesn't mean the pipeline becomes easy. the LLM also requires parameters and prompt tuning to keep the output clean.
Further enchancement
Since the PoC is done, A am still not satisfied with the work I've done. it works for my daily life, but I need to improve further on the end-to-end performance and dashboard to match what i need
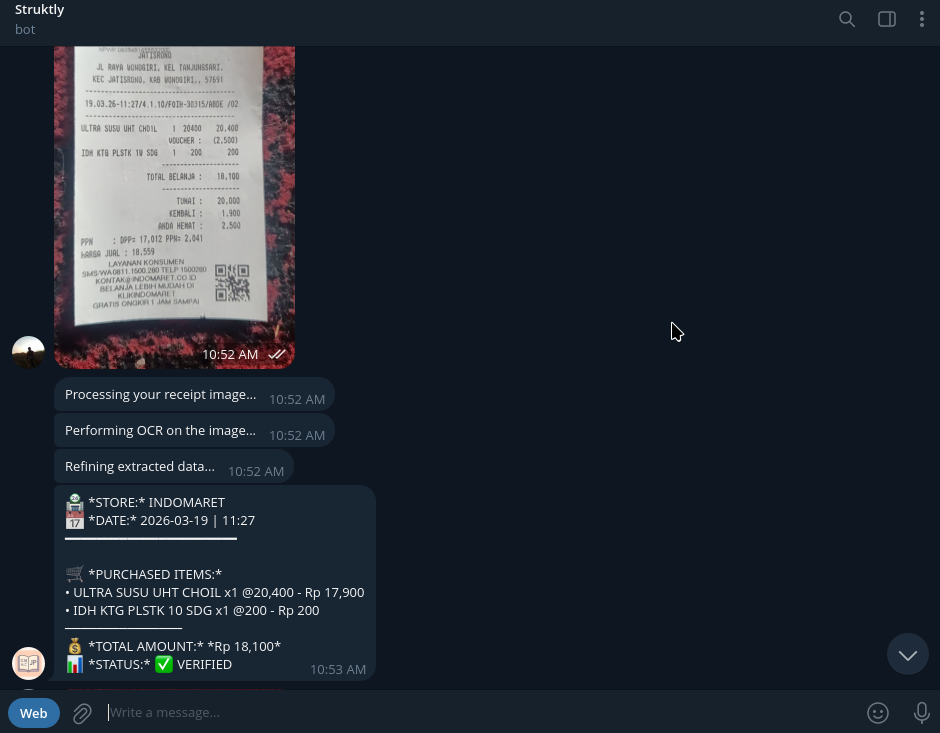
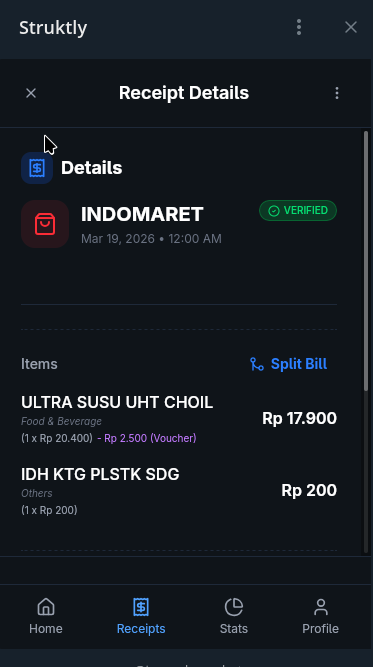
Result examples